Languages and Literacies
Im Potenzialbereich "Languages and Literacies" untersuchen Forschende der Erziehungs- und Geisteswissenschaften Phänomene sprachlicher Diversität und Herausforderungen sprachlicher Bildung in gesellschaftlichen Kontexten. Fächerübergreifend werden theoretisch Grundlagen, innovative Forschungszugänge und praxisrelevante Anwendungen erarbeitet.
Seit Gründung der Fakultät für Geisteswissenschaften (2005) wird ihr Profil aufgrund des exzellent bewerteten SFB 538 „Mehrsprachigkeit“ und seines wegweisenden Transferbereichs nachhaltig mit Mehrsprachigkeit und affiner Empirischer Linguistik nebst Korpusarchivierung (Hamburger Zentrum für Sprachkorpora, HZSK) in Verbindung gebracht. Nach dem Auslaufen der Landesexzellenzinitiative „Linguistic diversity management in urban areas (LiMA)“, die 2009-2013 von den Fakultät für Geisteswissenschaften und der damaligen Fakultät für Erziehungswissenschaft, Psychologie und Bewegungswissenschaft (EPB) getragen wurde, hat sich vor dem Hintergrund darin bewährter fachbereichsübergreifender Forschung der geisteswissenschaftliche Schwerpunkt „Linguistic Diversity / Sprachliche Diversität“ neu konturiert.
In diesem fakultären Schwerpunkt werden seit 2014 Aktivitäten gebündelt, die in interdisziplinärer, teilweise auch transdisziplinärer Weise das breitere Spektrum sprachlicher Diversität behandeln. Es geht um historische und gegenwärtige, sozial und kulturell oder ethnisch sowie kognitiv begründete sprachliche Varietäten, um medial bedingte Unterschiede sprachlicher Kommunikation ebenso wie um individuelle und gesellschaftliche Mehrsprachigkeit im Zuge von Migration und Sprachkontakt und deren Transformation in institutionelle Strukturbedingungen. Maßnahmen des Zentrums für Sprachwissenschaft (ZfS) wie fachbereichsübergreifende Ringvorlesungen und die Pilotierung innovativer Lehrkonzepte und Kolloquien sowie konzertierte und einzelne Forschungsplanungen greifen hierzu ineinander.
Dieses Zusammenwirken dokumentiert sich in vielfältigen Vernetzungen: mit Akademien in den Langzeitprojekten, mit in- und ausländischen Universitäten in Verbünden und Einzelprojekten und innerhalb der UHH in Kooperationen über die Fakultätsgrenzen hinaus sowie an Schnittstellen mit anderen fakultären Schwerpunkten. Die aktuell laufenden Projekte fokussieren Fragestellungen zur strukturellen Ausprägung und Entwicklung individueller wie gesellschaftlicher Mehrsprachigkeit und Sprachvariation in unterschiedlichen Handlungskonstellationen Deutschlands, Europas und außerhalb Europas.
Seit 2025 ist „Languages and Literacies“ gemeinsamer Potenzialbereich der Fakultät für Geisteswissenschaften und der Fakultät für Erziehungswissenschaft.
Zum Potenzialbereich gehören neben kleineren drittmittelfinanzierten Einzelprojekten die folgenden Vorhaben aus der Fakultät für Geisteswissenschaften:
Projekte
European Research Council (ERC)
Starting Grant "Naming the world: Semantic associations and form-meaning mappings in the mental lexicon across sign Languages (SemaSign)"
Projektleitung: Dr. Hope Morgan
(Fachbereich SLM I, Institut für Deutsche Gebärdensprache und Kommunikation Gehörloser)
Laufzeit: 2024–2029
Deutsche Forschungsgemeinschaft (DFG)
Forschungsgruppe 5317 "Praktiken der Personenreferenz: Personal-, Indefinit- und Demonstrativpronomen im Gebrauch"
Projektleitung: Prof. Dr.Wolfgang Imo
(Fachbereich SLM I, Institut für Germanistik)
Laufzeit: 2022–2026
Das Ziel der Forschungsgruppe besteht darin, mit Blick auf das Deutsche Forschungslücken in Bezug auf den Gebrauch von Personal-, Indefinit-, und Demonstrativpronomen, die zur Referenz auf an- und abwesende Personen eingesetzt werden, zu schließen. Dabei stehen folgende Fragen im Fokus: Welche Routinen und verfestigten Muster lassen sich diachron und synchron beschreiben und wie sind solche Routinisierungen zu erklären? Wie hängt Pronomengebrauch mit der Medialität und Materialität von Sprache zusammen? Was ist der Handlungsbezug von Pronomen, inwieweit sind Pronomen als Lösungsstrategien für kommunikative Probleme beschreibbar und inwieweit tragen sie zur Perspektivierung von Situationen bei? Welche Aspekte der Referenzherstellung in Bezug auf die Parameter Generizität und Spezifizität, Definitheit und Indefinitheit, Exklusivität und Inklusivität sowie Agentivität und Nicht-Agentivität sind für den Pronomengebrauch relevant? Die Forschungsgruppe setzt sich aus neun Projekten zusammen, die sich auf drei Universitätsstandorte verteilen. Das Forschungsprogramm verbindet die Perspektiven der interaktionalen und historischen Linguistik im Rahmen einer gebrauchsbasierten Theoriebildung: (1) Susanne Günthner/Wolfgang Imo: Praktiken der Personenreferenz: Der Gebrauch von Pronomina in onkologischen Aufklärungsgesprächen (Münster/Hamburg). (2) Antje Dammel: Referenzielle Praxis im Wandel: Das Pronomen man in der Diachronie des Deutschen (Münster). Jens Lanwer (Münster): Pronomen als Konstruktionsnetzwerk: Gebrauchsbasierte Analysen von Verfahren der Personenreferenz in verbal-mündlicher Interaktion (Münster). (4) Wolfgang Imo: Personenreferierende Pronomen in Dramen: interaktionale und dramaturgische Funktionen sowie historischer Wandel von Barock über Aufklärung zu Sturm und Drang und Klassik (Hamburg). (5) Irina Mostovaia: Pronomen als Konstruktionsnetzwerk: Gebrauchsbasierte Analysen pronominaler Verfahren der Personenreferenz in verbal-schriftlicher Interaktion (Hamburg). (6) Evelyn Ziegler: Wer ist wir? Der Gebrauch des Personalpronomens wir zur Bezugnahme auf Gemeinschaft im Kontext von Migration und Integration (Duisburg-Essen). (7) Melitta Gillmann: Referenz und Vagheit sprecher- und adressatenbezogener Personalpronomen in der deutschen Sprachgeschichte (Duisburg-Essen). (8) Karola Pitsch: Multimodalität von Personenreferenz: Pronominale Personenreferenz in Notfallübungen von Medizinern und Feuerwehr (Duisburg-Essen). (9) Maximilian Krug: Pronominale Personenreferenz in DDR-Leserbriefen: Kommunikative Funktionen von Personal-, Indefinit- und Possessivpronomen zur Herstellung sozialer Gruppenkategorisierung in einem autoritären System (Duisburg-Essen). An jedem Projektstandort sind zwei bis vier Teilprojekte situiert. An allen Standorten wird in der Kombination der Teilprojekte eine synchrone mit einer diachronen Perspektive verbunden.
Forschungsgruppe 5728 "Convergence on Dominant Language Constellations: World Englishes in their local multilingual ecologies" (CODILAC)
Projektleitung: Prof. Dr. Peter Siemund
(Fachbereich SLM II, Institut für Anglistik und Amerikanistik)
Laufzeit: 2025–2029
Die Forschungsgruppe vergleicht die Rolle des Englischen in sieben repräsentativen und heterogenen mehrsprachigen Weltregionen. Wir stellen Botswana, Cebu City (Philippinen), Zypern, die Region Kurdistan (Irak), Lagos (Nigeria), Nordostindien und Tansania einander gegenüber. Die Forschungsstelle arbeitet direkt mit lokalen Informanten auf der Grundlage von Fragebögen und persönlichen Gesprächen zusammen. Sie erstellt umfassende und vergleichbare Datensätze, die mit umfangreichen Informationen zum sozioökonomischen Hintergrund, zur Ethnografie und zum Sprachgebrauch angereichert sind.
Der Vergleich basiert auf den Konzepten der mehrsprachigen Ökologien, der Sprachrepertoires und der dominanten Sprachkonstellationen (DLCs). Die Forschungsgruppe postuliert und sucht nach gemeinsamen soziolinguistischen Mustern und Ergebnissen von Sprachkontakt, Migration und Globalisierung, ist aber auch an den einzigartigen lokalen Merkmalen und Unterschieden interessiert.
Langfristvorhaben "Wortfamilien diachron (WoDia) – Eine Forschungsumgebung zur historischen Wortbildung des Deutschen"
Projektleitung: Prof. Dr. Ingrid Schröder
(Fachbereich SLM I, Institut für Germanistik)
Beteiligte: Prof. Dr. Jost Gippert (Goethe-Universität Frankfurt am Main / Universität Hamburg), Dr. Thomas Burch (Kompetenzzentrum – Trier Center for Digital Humanities), Dr. Sarah Ihden (Universität Bonn / Universität Hamburg), Dr. Ralf Plate (Goethe-Universität Frankfurt am Main / Akademie der Wissenschaften und der Literatur | Mainz)
Laufzeit: 2024–2027 (1. Förderphase)
Einzelprojekte
Coactivating the difference in the verbal domain of German Sign Language: A developmental perspective at signers processing signing and reading (CoDiPro) (DFG)
Prof. Dr. Annika Herrmann (Fachbereich SLM I, IDGS), Prof. Dr. Barbara Hänel-Faulhaber (EW-Fakultät)
Laufzeit: 2023–2026
Propositionale Anaphern in negativ polaren Kontexten (Teilprojekt C10 des Kölner SFB "Prominenz in Sprache")
Prof. Dr. Stefan Hinterwimmer (Fachbereich SLM I, IfG), Prof. Dr. Sophie Repp (U Köln)
Laufzeit: 01.08.2025–31.12.2028
In diesem Projekt untersuchen wir die Prinzipien, die die anaphorische Wiederaufnahme von Propositionen in negativen Sätzen bestimmen. Wenn ein negativer Satz geäußert wird, besteht im Folgesatz generell die Möglichkeit mittels einer Anapher (z.B. dem Pronomen "das") auf die vom Satz denotierte negative Proposition (¬p) zuzugreifen, oder auf die nicht negierte Proposition (p). Meistens ist es jedoch so, dass eine der beiden Varianten bevorzugt ist, oder überhaupt die einzige mögliche Interpretation. Ziel des Projekts ist es, herauszufinden, welche Faktoren die Interpretation von Anaphern wie "das" beeinflussen. Mit anderen Worten untersuchen wir die Faktoren, die – laut Hypothese – die Prominenz von ¬p vs. p, und damit die anaphorische Wiederaufnahme von ¬p vs. p beeinflussen. Wir studieren diese Faktoren mittels experimenteller Erhebungen und Korpusstudien.
Visueller und nicht visueller Ausdruck von Perspektive in der Sprache II
Prof. Dr. Stefan Hinterwimmer (Fachbereich SLM I, IfG), Prof. Dr. Cornelia Ebert (U Frankfurt a. M.)
Laufzeit: 01.12.2025-30.11.2028
Nachdem in der ersten Projektphase das Zusammenspiel von Lautsprache und sprachbegleitenden Gesten im Zentrum stand, wollen wir in der zweiten Phase das Zusammenspiel von schriftsprachlich vermittelter Information mit in Abbildungen und Memes enthaltener Information beim Ausdruck von Perspektive untersuchen, u. a. auch im Hinblick auf die Frage, wie die beiden Modalitäten bei der Auf- bzw. Abwertung und Markierung von Individuen und Gruppen als Identifikationsobjekte bzw. Feindbilder zusammenwirken.
Akademie der Wissenschaften
Langzeitvorhaben "Entwicklung eines korpusbasierten elektronischen Wörterbuchs Deutsche Gebärdensprache (DGS) - Deutsch"
Projektleitung: Prof. Dr. Annika Herrmann, Thomas Hanke (seit 01.04.2017, zuvor: Prof. Dr. Christian Rathmann)
(Fachbereich SLM I, Institut für Deutsche Gebärdensprache und Kommunikation Gehörloser)
Laufzeit: 2009–2027
Unter Gehörlosen haben sich über Jahrhunderte visuelle Sprachen herausgebildet, die jedoch keineswegs identisch sind mit der gestischen Körpersprache Hörender: Vielmehr handelt es sich um eigenständige Sprachen, die über einen umfassenden Wortschatz und eine komplexe Grammatik verfügen. Lexikalische Gebärden sind nach Handform, Handstellung, Ausführungsstelle und Bewegung strukturiert und können nach linguistischen Regeln im sog. Gebärdenraum ausgeführt werden. Darüber hinaus spielen Mimik, Körperhaltung und Mundbewegungen für die Bildung von Sätzen und für den Aufbau von Texten eine große Rolle. Gebärdensprachen sind natürlich etablierte Sprachen: Die nationalen Gebärdensprachen unterscheiden sich zum Teil erheblich, Gebärdensprache ist also nicht – wie häufig angenommen – international. Auch innerhalb der Deutschen Gebärdensprache gibt es regionale Unterschiede.
In einem Langzeitprojekt der Akademie der Wissenschaften in Hamburg wird ein elektronisches, korpusbasiertes Wörterbuch der Deutschen Gebärdensprache erstellt. Das Projekt ist auf 15 Jahre angelegt (Beginn: 1. Januar 2009) und wird am Institut für Deutsche Gebärdensprache und Kommunikation Gehörloser der Universität Hamburg durchgeführt. Aus dem Akademienprogramm zur Förderung geisteswissenschaftlicher Grundlagenforschung, das von Bund und Ländern getragen wird, stehen dafür insgesamt 8,5 Mio. Euro zur Verfügung.
Ziel des Projekts ist zunächst eine umfassende Sammlung gebärdensprachlicher Daten: Hierzu wurden in der ersten Projektphase Gebärden von ca. 330 gehörlosen Informanten aus dem gesamten Bundesgebiet erhoben. Diese wurden per Video aufgezeichnet und werden fortlaufend systematisch, mithilfe einer eigens entwickelten Datenbank (iLex) verarbeitet und analysiert. Dieses Korpus, das mehrere hundert Stunden Videomaterial umfasst, bildet die Grundlage für die Erstellung des Wörterbuchs. Ein Teilkorpus wurde Ende 2015 veröffentlicht.
Die Auswahl der Stichwörter für das korpusbasierte Wörterbuch wird sich dabei in erster Linie auf die tatsächliche Gebärdenanwendung stützen – im Unterschied zu bisherigen Gebärdensammlungen, die von einer deutschen Wortliste ausgingen. Das Wörterbuch wird ca. 6000 Gebärdeneinträge umfassen. Es ist bidirektional angelegt, d.h. es kann in beide Richtungen nachgeschlagen werden, ausgehend von einer Ge-bärde oder einem deutschen Wort.
Da es sich bei der Gebärdensprache um eine visuelle Sprache handelt, wäre das Pro-jekt ohne moderne Technologien kaum denkbar: Die Gebärden werden als Filme gezeigt, die elektronische Datenbank erlaubt vielfältige Kombinations- und Such-strategien, z.B. auch die Suche nach Gebärdenformen.
Mit der Erstellung dieses Korpus und Wörterbuchs wird die in Deutschland verwen-dete Deutsche Gebärdensprache zum ersten Mal systematisch erfasst und analysiert. Während in der linguistischen Erforschung der Lautsprachen korpusbasierte Methoden mittlerweile sehr verbreitet sind, steckt die entsprechende Grundlagenforschung zur DGS noch in den Anfängen.
Die Erstellung eines DGS-Korpus ist von besonderer Bedeutung, da die DGS bisher kaum systematisch dokumentiert ist: Es existieren signifikante soziolinguistische Variationen (dazu zählen auch regionale und individuelle Unterschiede) in ihrer Verwendung. Diese verschiedenen Formen der DGS zu erfassen und zu dokumentieren, ist ein zentrales Ziel des Korpus. Über die Entwicklung des Wörterbuchs hinaus wird das Korpus auch langfristig eine Vielzahl von Möglichkeiten für die empirisch fundierte Erforschung der DGS bieten.
Für die Gehörlosengemeinschaft hat das Projekt auch einen hohen ideellen Wert: Die traditionelle Gehörlosenpädagogik wertete bis in die zweite Hälfte des 20. Jahrhunderts die Gebärdensprachen als bloßes nicht-sprachliches Gestikulieren ab; auch von der Sprachwissenschaft wurde sie kaum als Forschungsgegenstand wahrgenommen. Die Gebärdensprachgemeinschaft ist von Anfang an in die Erstellung des Korpus und des Wörterbuchs einbezogen – auch über die aktive Beteiligung der Gebärdensprach-Informanten hinaus: So wurde zu Beginn des Projekts eine Umfrage unter den potentiellen Nutzern des Wörterbuchs durchgeführt. Die verschiedenen Nutzergruppen – DGS-Muttersprachler wie gehörlose Erwachsene oder Kinder gehörloser Eltern, DGS-Lerner wie Spätertaubte, Eltern oder Lehrer gehörloser Kinder sowie Gebärdensprachdolmetscher und Linguisten – werden nach ihren Bedürfnissen und Erwartungen an das Wörterbuch befragt. Darüber hinaus findet seit einem Jahr ein Internet-basiertes Feedback-Verfahren statt, das es Mitgliedern der Gebärdensprachgemeinschaft erlaubt, ausgewähltes Material zu beurteilen und zu kommentieren. Eine laufend aktualisierte Projekthomepage informiert regelmäßig über den Fortgang des Projekts.
Langzeitvorhaben "Grammatiken, Korpora und Sprachtechnologie für indigene nordeurasische Sprachen"
Projektleitung: Prof. Dr. Beáta Wagner-Nagy
(Fachbereich SLM II, Institut für Finnougristik/Uralistik)
Laufzeit: 2016–2034
Das Vorhaben soll mithilfe eines innovativen und interdisziplinären Ansatzes, der Methoden der Dokumentations-, Korpus- und Computerlinguistik sowie der Grammatikographie bündelt, erstmalig die dringend erforderliche Erschließung der sprachlichen Ressourcen des genealogisch diversen nordeurasischen Sprachraums leisten. Die Sprachen des nordeurasischen Areals gehören vor allem in die zwei geographisch sehr weit verbreiteten Sprachfamilien Uralisch und Altaisch. Diese sind keineswegs unerforscht, der Forschungsstand unterscheidet sich jedoch von Sprache zu Sprache. Die größeren Sprachen, wie z.B. Komi und Nenzisch, sind vergleichsweise gut erforscht, obwohl sich die Forschung hier, so wie bei den meisten übrigen uralischen Sprachen, bisher vornehmlich auf die (historische) Phonologie und Morphologie konzentrierte. Andere Sprachen, wie z.B. das in Nordsibirien gesprochene Dolganisch, sind eher spärlich beschrieben, wenngleich das Volk der Dolganen und ihre Sprache in den letzten Jahren Gegenstand einiger anthropologischer und linguistischer Beschreibungen waren.
Durch den Einsatz von State-of-the-Art-Methoden und -Werkzeugen der linguistischen Datenaufbereitung, die bisher nur für gut erforschte Sprachen und Varietäten zum Einsatz kamen, wird eine Lücke in diesen für die empirische Sprachwissenschaft bisher schlecht zugänglichen Arealen der Welt nachhaltig geschlossen.
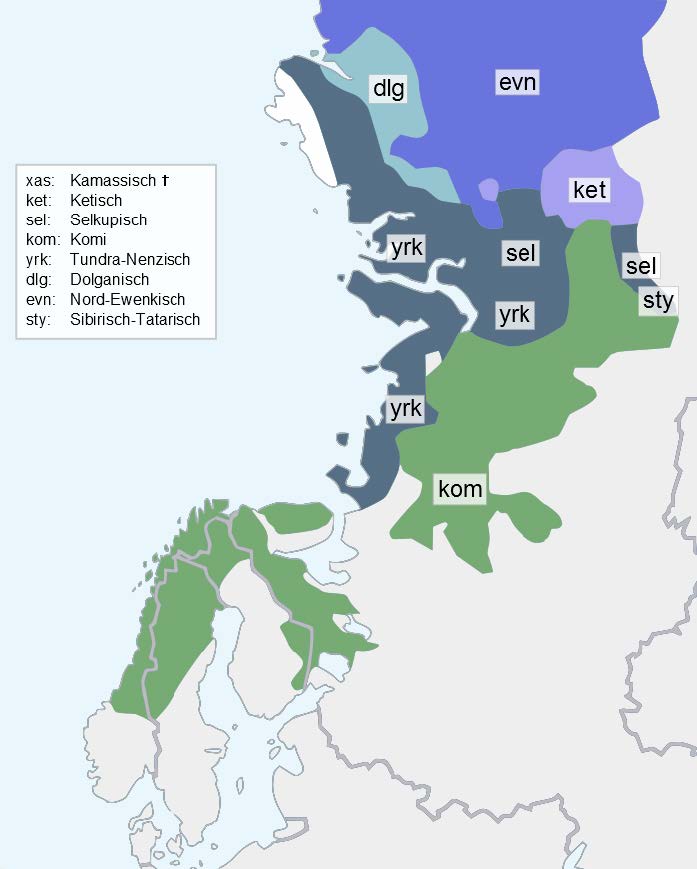
Aufgrund des drohenden Verfalls der zum großen Teil auf obsoleten Originalträgern (Wachswalzen, Schellackplatten, Mikrofiche etc.) in verschiedenen Archiven gelagerten Audio-Aufnahmen, Niederschriften und Beschreibungen schließt sich in absehbarer Zeit das Zeitfenster für einen Erhalt der Daten und somit auch für eine Überlieferung an kommende Generationen. Gleichzeitig gehen die Sprecherzahlen vieler Sprachen und Varietäten stetig zurück. Indem existierende Materialien zu digitalen Korpora (maschinenlesbaren mit linguistischen Informationen angereicherten empi-rischen Ressourcen) aufbereitet und der bisherige Gesamtbestand um neue Korpora ergänzt wird, kann dieses Erbe als wertvolle empirische Basis für vielfältige Forschungsvorhaben erhalten werden. Vielmehr als nur ein digitales Archiv wird das Resultat dieses Vorhabens jedoch eine umfassende virtuelle Forschungsumgebung sein, die durch die Integration in supranationale Forschungsinfrastrukturen der wissenschaftlichen Öffentlichkeit dauerhaft zugänglich gemacht wird. Der innovative Charakter des Vorhabens besteht somit zunächst darin, existierende Beschreibungen einzelner nordeurasischer Sprachen und Varietäten, die aufgrund der bisher be-grenzten Auswahl von verfügbaren Sprechern und Genres eher partikuläre Idiolekte dokumentieren, zusammenzutragen und mit ergänzenden Korpora als umfangreiche digitale Ressource zugänglich zu machen. Durch die so geschaffene, der Vielfalt der Sprache angemessene Datenbasis werden für zukünftige Generationen von Forschenden erstmalig varietätenübergreifende Analysen möglich, etwa die Erforschung kontaktinduzierter Sprachveränderungen, Anwendungen aus dem Bereich der Dialektometrie oder sprachsoziologische Untersuchungen. Die unterschiedlichen Erhebungszeiten der Sprachdaten erlauben zudem erstmalig datengestützte Unter-suchungen von diachronem Sprachwandel sowie Grammatikalisierungsprozessen.
Ebenso bedeutend sind die innovative Art des Zugangs zu den Sprachdaten und die damit verbundenen Analysemöglichkeiten. Die Sprachdaten können in der Forschungsumgebung kollaborativ und dezentral um beliebige weitere Beschreibungsebenen angereichert werden, die dann für verschiedene Auswertungsszenarien zur Verfügung stehen. So weit wie möglich werden für Aufbereitung und Analyse automatisierte Verfahren eingesetzt, die jeweils als einzelne Komponenten der Forschungsumgebung realisiert werden können. Auf diese Weise wird die virtuelle Forschungsumgebung modular aufgebaut und in vielen Fällen so generisch sein, dass auch die Resultate technologischer und methodologischer Entwicklungen der akademischen Öffentlichkeit als Best Practices und als konkrete Grundlage für vergleichbare Vorhaben zur Verfügung stehen werden.
Langzeitvorhaben "Historische Fremdsprachenlehrwerke digital. Sprachgeschichte, Sprachvorstellungen und Alltagskommunikation im Kontext der Mehrsprachigkeit im Europa der Frühen Neuzeit (FSL digital)"
Projektleitung: Prof. Dr. Natalia Filatkina
(Fachbereich SLM I, Institut für Germanistik),
Prof. Dr. Horst Simon (FU Berlin), Prof. Dr. Andrea Rapp (TU Darmstadt)
Laufzeit: 2024–2042
Das Langzeitvorhaben (Akademienprogramm 2024 der Union der deutschen Akademien) widmet sich erstmalig der Volltexterschließung, korpuslinguistischen Aufbereitung, Annotation, digitalen Vernetzung sowie der sprach-, kultur- und wissenshistorischen Auswertung von mehrsprachigen Fremdsprachenlehrwerken (FSL) aus der Frühen Neuzeit mit einem Schwerpunkt auf den Deutsch beinhaltenden Werken.
Das Projekt setzt sich zum Ziel, die praktischen Formen der Vermittlung des Wissens über die Vernakularsprachen (Aussprache, Grammatik, Wortschatz, Pragmatik) sowie der schriftlichen und vor allem der mündlichkeitsnahen Alltagskommunikation im mehrsprachigen Kontext des frühneuzeitlichen Europa zu erschließen und zu untersuchen. Auf diese Weise wird ein Paradigmenwechsel angestrebt, insofern als ein Beitrag zu den europäischen Sprach(en)geschichte(n), zur Erforschung von Sprachkontakt und zum Fremdsprachenerwerb anhand der im gesamten Europa überlieferten, aber bis jetzt kaum untersuchten Quellen geleistet wird, deren Autoren eine sozial heterogene Gruppe der sogenannten Sprachmeister bildeten und zu deren praxisbezogenen Sprachvorstellungen (im Unterschied zum zeitgenössischen theoretischen Gelehrtendiskurs) kaum Forschungsergebnisse vorliegen. Im Rahmen des Vorhabens wird das gesamte überlieferte Material, in dem das Deutsche eine der Sprachen ist (ca. 1044 FSL; insgesamt ca. 626.400.000 Zeichen) nach einem gestuften Konzept volltexterschlossen, nachhaltig aufbereitet und für weitere Analysen bereitgestellt. Damit wird es zum ersten Mal möglich sein, die historischen Wurzeln der heutigen Mehrsprachigkeit in Europa aus der Perspektive alltagssprachlicher Praxis des Fremdsprachenerwerbs und der Fremdsprachen- und Wissensvermittlung in der Frühen Neuzeit zu beantworten.
Das Projekt unter der Hamburger Leitung von Prof. Dr. Natalia Filatkina ist eine Kooperation der Berlin-Brandenburgischen Akademie der Wissenschaften und der Akademie der Wissenschaften und der Literatur Mainz. Die Arbeitsstelle Hamburg wird von Dr. Kerstin Roth und Miriam Hinterholzer geleitet.
Freie und Hansestadt Hamburg
BSFB: Wissenschaftliche Aufarbeitung des Leids tauber und schwerhöriger Kinder an Hamburger Schulen (WAL-GL-HH)
Projektleitung: Prof. Dr. Annika Herrmann, Prof. Dr. Liona Paulus
(Fachbereich SLM I, Institut für Gebärdensprache und Kommunikation Gehörloser)
Laufzeit: 2026–2028
In Zusammenarbeit mit dem Gehörlosenverband Hamburg und der Elbschule (Bildungszentrum Hören und Kommunikation) erforscht das Institut für Deutsche Gebärdensprache in einem neuen von der BSFB und der Sozialbehörde geförderten Projekt leidvolle Erfahrungen ehemaliger tauber und schwerhöriger Schüler:innen in Hamburg zwischen ca. 1960 und 1990. Bildungsstätten für taube und schwerhörige Kinder gibt es in Hamburg seit 1827. Bis ca. 2000 wurden diese Schulen meist getrennt nach Gruppen geführt (Gehörlosenschule bzw. Schwerhörigenschule) und dann nach 2000 zusammengelegt. Die schulische Praxis war in Deutschland stark vom Oralismus geprägt, einer Methode, bei welcher der Fokus auf Lautsprache und Lippenlesen lag, während die Deutsche Gebärdensprache häufig verboten und allein die informelle Nutzung bereits bestraft wurde, und das bis in die 2000er Jahre hinein. Damit verbunden waren dementsprechend erhebliche körperliche und seelische Traumata, soziale Isolation und Diskriminierung. Im Jahr 2025 entschuldigte sich die Hamburger Bürgerschaft offiziell bei den Betroffenen für die leidvollen Erfahrungen. Das an der Fakultät GW angesiedelte Projekt WAL-GL-HH, geleitet von Prof. Dr. Liona Paulus und Prof. Dr. Annika Herrmann am IDGS in Kooperation mit dem Hamburger Gehörlosenverband, vertreten durch Alexander von Meyenn und Christian Ebmeyer, und der Elbschule hat zum Ziel, die strukturelle Gewalt und die Langzeitfolgen des oralistischen Systems an tauben und schwerhörigem Schüler:innen in Hamburg zu erfassen und zu dokumentieren. Methodisch werden qualitative Interviews mit Peer-Personen, Literaturrecherchen und Quellenarbeit durchgeführt. Die Erhebung erfolgt unter Einhaltung höchster ethischer datenschutzrechtlicher Standards und mit Rücksicht auf die Wünsche der Betroffenen. Das Projekt soll das physische und psychische Leid sichtbar machen, das Erlebte nachvollziehbar dokumentieren und die Betroffenen in ihrer Würde stärken. Somit entsteht eine wissenschaftliche Basis zur Aufarbeitung eines dunklen, bisher unsichtbaren Teils der Schulgeschichte Hamburgs.
Landesforschungsförderung (LFF): Internationale Kooperation "Unsichtbare Frauen. Neue Perspektiven auf eine Sprachgeschichte der Frau"
Projektleitung: Dr. Julia Hübner (Fachbereich SLM I, Institut für Germanistik)
Laufzeit: 2025–2027
Die Sprachgeschichte der Frau ist gemeinhin die Geschichte der außergewöhnlichen Frau. Frauen von niedrigem Stand und Frauen ohne öffentliches Ansehen bleiben hingegen oft unsichtbar. Für eine Darstellung des kollektiven frühneuzeitlichen Sprachsystems ist das jedoch unzureichend. Gleichzeitig ist das Bild der Frau vorwiegend durch die Perspektive (gelehrter) Männer geprägt und repräsentiert angestrebte gesellschaftliche Normen oder eine Idealvorstellung. Durch die Sichtbarmachung bisher unsichtbarer Frauen werden neue Erkenntnisse für eine erweiterte Frauen(sprach)geschichte gewonnen.
Erasmus+ Cooperation Partnerships
DAI: Developing an Al-assisted Italian Language Teaching and Learning System
Projektleitung: Prof. Dr. Jacopo Torregrossa (Universität Frankfurt), Prof. Dr. Luigi Andriani (Fachbereich SLM II, Institut für Romanistik)
Laufzeit: 2025–2028
The project aims to improve Italian as a foreign language instruction through the integration of AI. Its core objectives are to:
- provide students with a personalized, AI-based training package;
- equip teachers with the digital and AI skills needed for effective integration of these technologies;
- offer a comprehensive resource library for both teachers and learners;
- gather a learner corpus from the online course for research purposes.
This initiative seeks to transform teaching practices by leveraging AI's potential for tailored education.